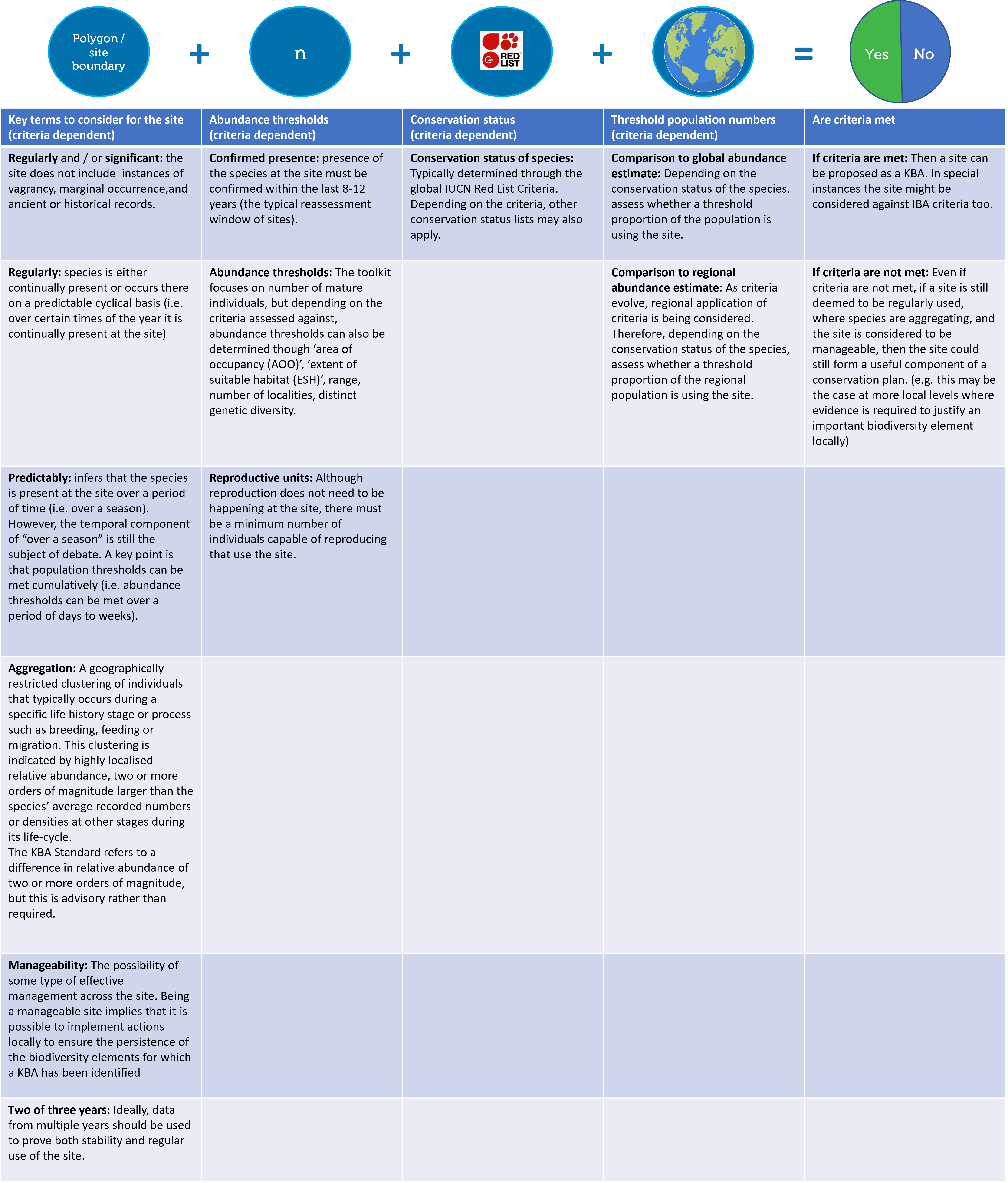
14 Data needs: Identifying a site
As per the chapter “Sites: Toolkit context”
The typical data needed to identify site types outlined in the toolkit are:
data used to define a boundary which can be considered as a site (e.g. tracking data, or ability to identify a known area used by animals), and knowledge of how the species uses the site. The data should also enable users to create a spatial polygon file (typically a shapefile)
an abundance estimate for the site (the Toolkit focuses on mature individuals as the key unit for determining abundance)
the conservation status of the species (typically the global IUCN Red List Status)
a global abundance estimate
With those data, one can determine whether or not a site meets relevant criteria.
In the toolkit, while we recognise a spectrum of sites, we advocate for, and support the identification of, Key Biodiversity Areas (KBAs). This is because by formally identifying a site as a KBA, the site will have added ability to bring about a change by a decision-maker that supports species maintaining or achieving a favourable conservation status.
Below, summarises some of the key concepts with regards to identifying a site for the conservation of marine megafuana, particularly through a KBA approach.